Architecture Overview アーキテクチャの概要
Let’s go over the architecture of the transformer.
トランスフォーマーのアーキテクチャを見ていきましょう。
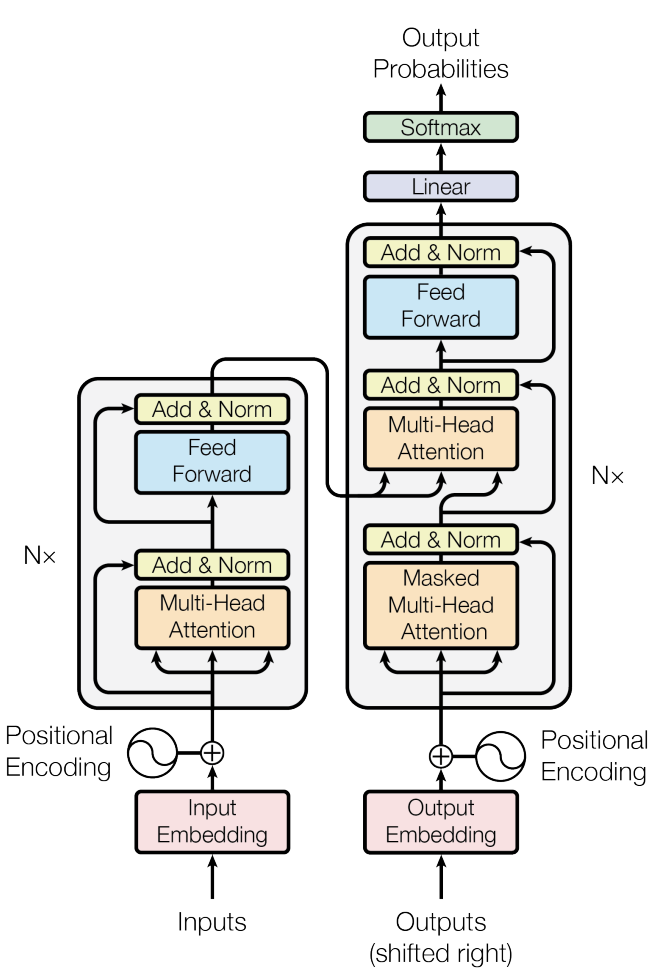
In this diagram, the left side is the encoder, and the right side is the decoder. Notice the on the side of both parts. Right below the diagram, they say both encoder and decoder consist of identical layers. So the output of one stack on the encoder side goes into the next stack, repeating 6 times, and the same happens on the decoder side too.
この図では、左側がエンコーダー、右側がデコーダーです。両側にと書かれていることに注目してください。図の下で、エンコーダーとデコーダーはそれぞれ個の同一レイヤーで構成されるという説明があります。つまり、エンコーダー側では1つのスタックの出力が次のスタックへ入力され、これが6回繰り返されます。デコーダー側も同様です。
To make the discussion concrete, we are going to use a translation from English to French.
議論を具体的にするために、英語からフランス語への翻訳を例として用います。
Encoder Process
エンコーダーのプロセス
The Input Embeddings are the tokens for the English text encoded as vectors. In this paper, the embeddings are 512-dimensional. If the original sentence is broken down into tokens this way, the input is a array.
Input Embeddings は、英語のテキストのトークンをベクトルとしてエンコードしたものです。この論文では、埋め込み(Embeddings)は512次元です。元の文が次のようにトークンに分解される場合、入力は の配列になります。
The encoder takes these initial embeddings and adds Positional Encoding—information about each token’s position. The gray box is the main processing component. It contains 6 identical layers, so the process repeats 6 times. The output from the first layer becomes the input for the second, and so on. Throughout this process, the encoder maintains the same shape: a array.
エンコーダーはこれらの初期埋め込みを受け取り、位置エンコーディング (各トークンの位置情報) を追加します。灰色のボックスがメイン処理コンポーネントです。これは6つの同一レイヤーで構成されているため、処理は6回繰り返されます。最初のレイヤーからの出力が2番目のレイヤーの入力となり、以降も同様に続きます。この処理全体を通じて、エンコーダーは同じ形状を維持します: の配列です。
The encoder’s job is to add context to each token.
エンコーダーの役割は、それぞれのトークンに文脈を追加することです。
While we usually think a word has a clear, fixed definition, in reality, meaning is often ambiguous. “Apple” might be a fruit, a tech company, or a nickname for New York City. We don’t know who the “I” is in this short sentence, but in a novel, “I” might be a specific character.
単語には明確で固定された定義があると考えがちですが、実際には大抵曖昧なものです。「Apple」は果物かもしれないし、テクノロジー企業かも、ニューヨーク市のニックネームかもしれません。この短い例文では「I」が誰なのかわかりませんが、小説であれば「I」は特定のキャラクターを指すかもしれません。
The encoder looks at the entire sequence simultaneously. Using a process called Self-Attention, it adjusts each token’s high-dimensional embedding to represent a more accurate, nuanced meaning. For example, the encoder nudges the “apple” vector toward the “fruit” cluster because it sees the “ate” vector nearby. By the 6th layer, the embedding for “apple” has shifted in 512-dimensional space to represent something like: “the fruit that was eaten by the narrator (I).”
エンコーダーはシーケンス全体を同時に把握し、自己アテンション(Self-Attention)と呼ばれるプロセスを用いて、それぞれのトークンの高次元埋め込みを調整し、より正確な意味やニュアンスを表現します。例えば、エンコーダーは近くに「ate」ベクトルがあることを認識して、「apple」ベクトルを「果物」の集まりの方向に微調整します。6番目のレイヤーに辿り着く頃には、「apple」の埋め込みは512次元空間内で移動して、「語り手(I)によって食べられた果物」といった意味を持つようになります。
These tokens in the example aren’t exactly what the model used or generated, but the details don’t matter for understanding the mechanism. Also, I wrote the embedding’s meaning as a sentence for clarity, but remember: embeddings are just vectors, or positions in multi-dimensional space, and can’t be perfectly translated into human language.
この例のトークンは、モデルが実際に使用したものとは厳密には異なりますが、メカニズムを理解する上では問題ありません。また、埋め込みの意味を文章で表現しましたが、埋め込みは本来ベクトル、つまり多次元空間における位置であり、人間の言語に完全に翻訳できるものではないことを忘れないようにしましょう。
Decoder Process
デコーダーのプロセス
If the Encoder is about understanding, the Decoder is about generating. It uses the contextualized meaning from the Encoder to start building the output in French, one token at a time.
エンコーダーが理解を担当するのに対し、デコーダーは生成を担当します。デコーダーはエンコーダーからの文脈を与えられた意味を用いて、フランス語の出力を一度に1トークンずつ構築していきます。
The diagram may seem a little confusing because “Output Embeddings” feeds into the decoder. Think of the decoder as a machine that builds output tokens through iterations—it takes the previous state and adds the next token to it. The output embeddings here represent the text the decoder has generated so far.
図では「Output Embeddings」がデコーダーに入力されているため、少し混乱するかもしれません。デコーダーは反復処理を通じて出力トークンを構築する機械だと考えてください。つまり、前の状態を受け取り、次のトークンをそれに追加していきます。ここでの Output Embeddings は、デコーダーがこれまでに生成したテキストを表しています。
The output token starts with (beginning of sentence).
出力トークンは(文の始まり)からスタートします。
Similar to the encoder, the decoder adds positional encoding to the embeddings, then processes this through six layers. It uses Self-Attention to look at the French words it has already written to understand the flow, and Cross-Attention to look at the Encoder’s output to decide the next output token.
エンコーダーと同様に、デコーダーは埋め込みに位置エンコーディングを追加し、それを6つのレイヤーで処理します。デコーダーは自己アテンション(Self-Attention)を用いて、すでに書いたフランス語の単語を見て流れを理解し、交差アテンション(Cross-Attention)を用いてエンコーダーの出力を見て次の出力トークンを決定します。
After the 6th layer, the model extracts the final vector with all the necessary context added to the previous token. The Linear layer computes the dot product between this vector and all French vocabulary words (which are also encoded as 512-dimensional vectors) to calculate the likelihood of each possibility. The Softmax layer then converts these scores into probabilities that sum to 1.
6番目のレイヤーの後、モデルは直前のトークンに必要なすべての文脈を加えた最後のベクトルを取り出します。線形層(Linear layer)は、このベクトルとすべてのフランス語のボキャブラリー(こちらも512次元ベクトルとしてエンコードされています)との内積を求めて、それぞれの可能性を計算します。その後、ソフトマックス層(Softmax layer)がこれらのスコアを、合計が1になる確率に変換します。
The model adds the most aligned token, in this case “J’”, to the output embeddings, and feeds the new set of embeddings (now ) back into the next iteration. This process repeats until (end of sentence) is selected to signal the end.
モデルは最も整合性の高いトークン、この場合は「J’」を出力埋め込みに追加し、新しい埋め込みのセット(今は)を次の反復処理にフィードバックします。このプロセスは、終了の合図として(end of sentence)が選ばれるまで繰り返されます。
Next
次へ
On the next page, we’ll take a close look at the attention mechanism, which is the most important and innovative part of the architecture.
次のページでは、アーキテクチャの中で最も重要で革新的な部分である、アテンション機構について詳しく見ていきます。