Conclusions and Applications 結論と応用
Conclusions
結論
After explaining the architecture, the rest of the paper covers their tests and claims over a few sections. Skipping the detailed data, below is a brief summary of the key points.
アーキテクチャの説明の後、論文の残りの部分では、いくつかのセクションにわたって彼らのテストと主張が述べられています。詳細なデータは省略し、以下に要点の簡単なまとめを示します。
Why Attention?
なぜ自己アテンションを使うのか
Here the authors reiterate the motivation for choosing the attention mechanism over recurrent or convolutional layers based on factors such as Computational Efficiency, Parallelization, and Learning Long-Range Dependencies.
ここで著者らは、計算効率、並列化、長距離依存関係の学習といった要因に基づいて、再帰型や畳み込みではなくアテンション機構を選んだ動機を改めて述べています。
Training and Results
トレーニングと結果
These sections summarize their tests and results as proof of concept. I’ll skip the technical details, but the key result is that the model achieved a 28.4 BLEU score on English-to-German and 41.8 on English-to-French, significantly outperforming previous recurrent and convolutional models.
これらのセクションでは、理論の実証としてテストの結果をまとめています。技術的な詳細は省略しますが、重要な結果は、このモデルが英語からドイツ語への翻訳で28.4のBLEUスコア、英語からフランス語への翻訳で41.8を達成し、以前のリカレントモデルや畳み込みモデルを大幅に上回ったということです。
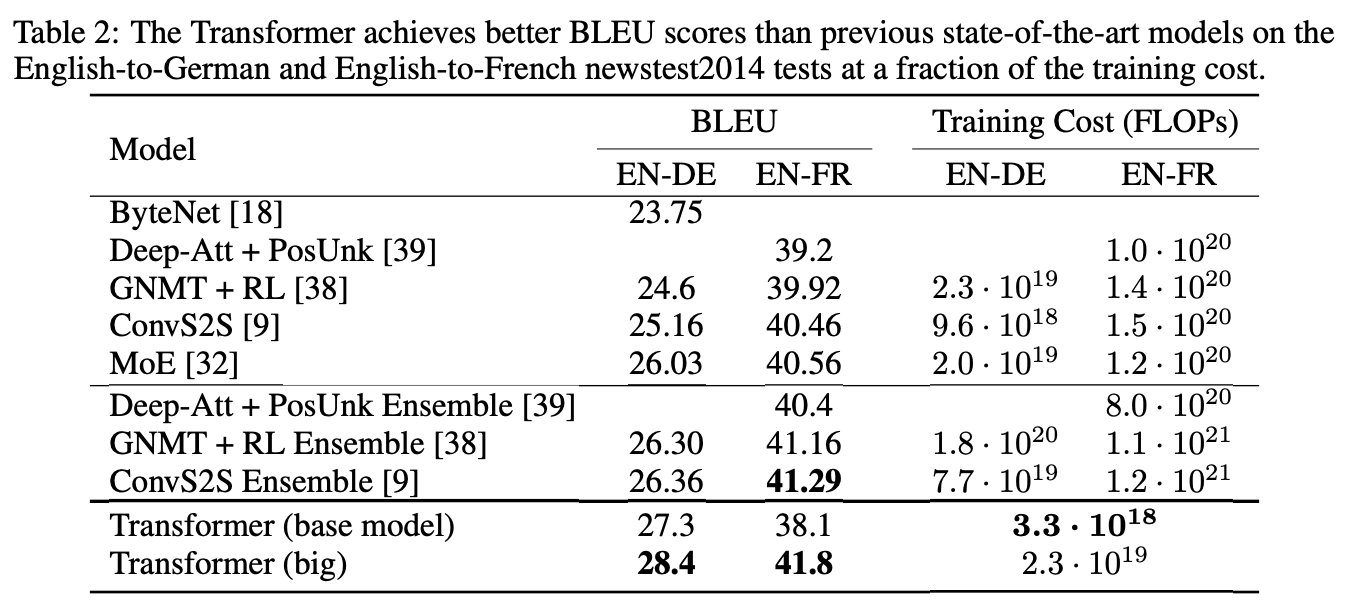
BLEU (Bilingual Evaluation Understudy) measures machine translation quality by counting overlapping words and phrases between AI output and human references while penalizing overly short sentences to avoid cheating. It’s not a perfect metric since it doesn’t check the actual meaning, but it’s commonly used because it can be automated. Scores range from 0 to 100, and 40–50 is considered hard to distinguish from human translation.
BLEU(Bilingual Evaluation Understudy)は、AIの出力と人間の参照訳で重複する単語やフレーズを数えて機械翻訳の品質を測定します。不正を避けるため、過度に短い文にはペナルティを課します。実際の意味は評価しないため完璧な指標ではありませんが、自動化できるため広く使われています。スコアは0から100の範囲で、40〜50は人間の翻訳と区別が難しいレベルとされています。
Training cost is another breakthrough. FLOPs are the estimated number of floating-point operations used to train a model. According to the chart, transformers require one or two orders of magnitude fewer than older models.
訓練コストも大きな進歩を見せました。FLOPsはモデルの訓練に必要な浮動小数点演算の推定数を示します。表によると、トランスフォーマーは従来のモデルと比べて1〜2桁少ない演算で済みます。
Additionally, they proved the model’s versatility by applying it to English constituency parsing. Constituency parsing breaks a sentence down into a semantic tree structure, which is a very different task than translation. They found that “despite the lack of task-specific tuning our model performs surprisingly well.”
さらに、英語の句構造解析への適用により、モデルの汎用性が証明されました。句構造解析は文を意味的な木構造に分解するタスクで、翻訳とは全く異なります。結果として「タスク固有のチューニングなしでも、モデルは驚くほど良好な性能を示した」とされています。
A note on parallelization
並列化に関する補足
This point is not clearly explained in the paper, but as we’ve seen in the introduction, parallelization is a major advantage of the transformer. But doesn’t the decoder generate output one by one? Actually, the advantage is more in the training phase. With the masking mechanism, we can produce all the states the model will go through, i.e., predicting the second token, the third token, etc. All these can be executed as parallel tasks independent of each other.
この点は論文で明確に説明されていませんが、導入部で見たように、並列化はトランスフォーマーの大きな利点です。しかし、デコーダーは出力を1つずつ生成するのではなかったでしょうか。実は、この利点はトレーニングの段階でより顕著に現れます。マスキング機構により、モデルが経るすべての状態、つまり2番目のトークンの予測、3番目のトークンの予測などを生成でき、これらはすべて互いに独立した並列のタスクとして実行できるのです。
What happened later
その後に起きたこと
We are excited about the future of attention-based models and plan to apply them to other tasks. We plan to extend the Transformer to problems involving input and output modalities other than text and to investigate local, restricted attention mechanisms to efficiently handle large inputs and outputs such as images, audio and video. Making generation less sequential is another research goals of ours.
我々はアテンションベースのモデルの将来性に期待しており、他のタスクへの適用を計画している。トランスフォーマーをテキスト以外の入出力モダリティ(形式)を含む問題へと拡張し、画像、音声、動画などの大規模な入出力を効率的に処理するための、局所的で制限されたアテンション機構の研究を行う予定である。また、生成プロセスをより非逐次的なものにすることも、我々の研究目標の1つである。
The paper concludes with a hopeful and ambitious remark. But the transformer has proven far more successful than the authors likely anticipated.
論文は希望に満ちた意欲的な言葉で締めくくられています。しかし、トランスフォーマーはおそらく彼らの予想をはるかに超えて成功を収めることになりました。
The most famous modern LLMs, like GPT series, Claude, and Gemini are based on the transformer but they use only the decoder part as generative models. Basically these models predict the next token based on all previous tokens, including user prompts, previous AI responses and other hidden contexts such as system prompts and retrieval from other sources and tools.
GPTシリーズ、Claude、Geminiなどの現代の最も有名なLLMはトランスフォーマーに基づいていますが、生成モデルとしてデコーダー部分のみを使用しています。これらのモデルは、ユーザープロンプト、以前のAI応答、システムプロンプトや他のソースやツールからの検索などの隠れたコンテキストを含む、前のトークンすべてに基づいて次のトークンを予測します。
The authors’ goal to handle images, audio, and video has been realized through Vision Transformers (ViT) and multimodal models, which treat images, audio, and videos as sequences of small patches and apply the self-attention mechanism.
著者らが目指していた画像、音声、動画の処理は、Vision Transformers(ViT)やマルチモーダルモデルによって実現されました。これらのモデルは、画像、音声、動画を小さなパッチの連続として扱い、自己アテンション機構を適用します。
That’s it for this article. Reading the original paper can be challenging. These papers are often dense and focus only on what’s new without explaining the background knowledge too much. But, it’s a rewarding experience to follow the authors’ thinking process. Hope you enjoyed the journey.
この記事は以上です。原論文を読むのは難しいかもしれません。こうした論文は内容が圧縮されていて、背景知識をあまり説明せず、新しい内容だけに焦点を当てているからです。しかし、著者の思考プロセスを追うことは、やりがいのある経験です。この旅を楽しんでいただけたなら幸いです。