Attention Mechanism アテンション機構
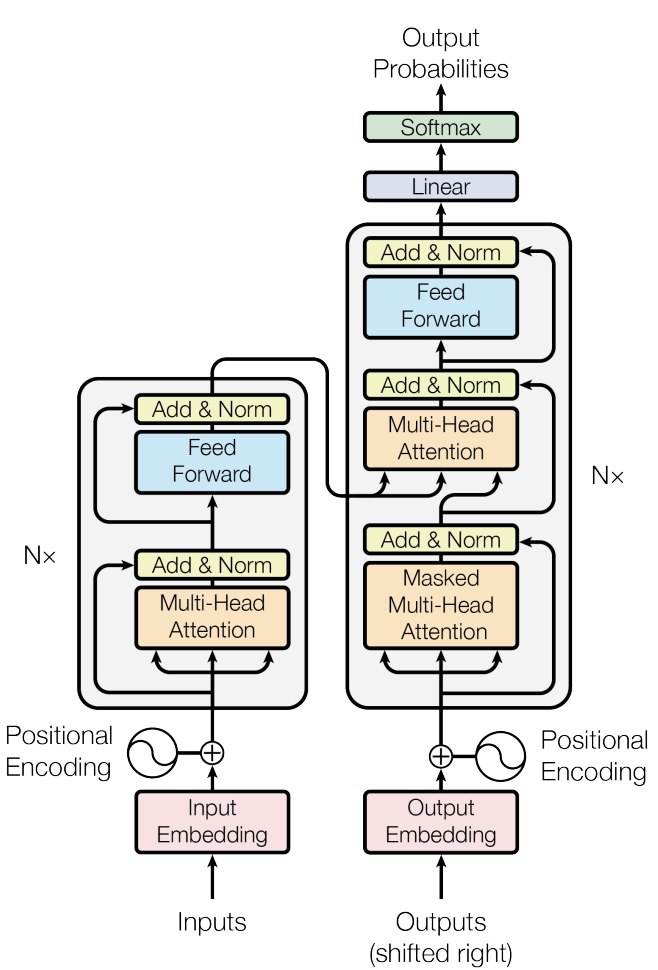
Now that we understand the overall architecture, let’s explore the paper’s most important concept—the attention mechanism. The diagram shows three orange boxes labeled “attention.” Each serves a different purpose, but all share the same structure.
全体的なアーキテクチャを理解したところで、この論文で最も重要な概念であるアテンション機構について見ていきましょう。図には「attention」とラベルがついたオレンジ色のボックスが3つあります。それぞれ異なる目的を果たしていますが、すべて同じ構造を共有しています。
What is attention?
アテンション(注意)とは
Roughly speaking, attention in this model means assigning weights to other vectors when processing a particular vector.
大まかに言えば、このモデルにおけるアテンションとは、特定のベクトルを処理する際に他のベクトルに重みを割り当てることを指します。
In the encoder, this determines how much each token relates to others. For example, when processing , the most important contextual token is because it clarifies what “apple” means in this sentence (it’s something the narrator ate, so it’s likely a fruit, not a company or a city).
エンコーダーでは、それぞれのトークンが他のトークンとどの程度関連しているかが決まります。例えば、を処理する際には、この文における「apple」の意味を明確にするが、文脈上最も重要なトークンです(話者が食べたものなので、企業名や都市名ではなく、果物である可能性が高い)。
There are two attention boxes in the decoder.
デコーダーには2つのアテンションボックスがあります。
Masked Multi Head Attention assigns weights to all previous French tokens, indicating which ones matter most for predicting the next token. For example, after writing “J’ai” (I have), it assigns a very high weight to “ai” because this auxiliary verb requires the next word to be a past participle.
Masked Multi Head Attention は、それまでのすべてのフランス語のトークンに重みを割り当て、次のトークンを予測する上でどれが最も重要かを示します。例えば、「J’ai」(私は持っている)を書いた後、「ai」に非常に高い重みを割り当てます。この助動詞の後には過去分詞が必要だからです。
The second attention box takes the output from the encoder, the contextualized input tokens. The weights here are the importance of each English token for predicting the next French token. For example, after writing “J’ai” (I have), the next token is most likely a verb, thus the token gets the highest weight.
2つ目のアテンションボックスは、エンコーダーからの出力、つまり文脈化された入力トークンを受け取ります。ここでの重みは、次のフランス語トークンを予測する上での各英語トークンの重要度を表します。例えば、「J’ai」(私は持っている)を書いた後、次のトークンは動詞である可能性が最も高いため、トークンの重みが最も高くなります。
The attention formula
アテンションの公式
The above is my best effort to describe what the mechanism does in plain English. The authors’ description actually looks a lot more technical and abstract.
上ではこの仕組みをできるだけ簡単な日本語で説明してみましたが、著者たちによる実際の説明はもっと技術的で抽象的です。
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
アテンション関数は、クエリ(Query)とキー・バリュー(Key-Value)ペアの集合を単一の出力へとマッピングするものとして記述できる。ここで、クエリ、キー、バリュー、および出力はすべてベクトルである。出力はバリューの重み付き和として計算され、それぞれのバリューに割り当てられる重みは、クエリと対応するキーとの適合性関数(Compatibility Function)によって計算される。
They call their attention mechanism “Scaled Dot-Product Attention” and define it with the formula below.
彼らは自分たちのアテンション機構を「Scaled Dot-Product Attention」と呼び、以下の公式で定義しています。
Let’s use the encoder as an example to examine what’s happening here more concretely. We will use the same input as the previous page.
エンコーダーを例に、ここで何が起こっているのかをより具体的に見ていきましょう。前のページと同じ入力を使います。
In the encoder, we derive our three matrices from our input .
エンコーダーでは、入力から3つの行列を求めます。
-
(The Queries)
-
(The Keys)
-
(The Values)
Where is the matrix of all input tokens () and each is a trainable weight matrix (). Consequently, , and are all arrays.
ここで、はすべての入力トークンの行列()であり、それぞれの は学習可能な重み行列()です。その結果、およびはすべて の配列になります。
The Fuzzy Dictionary Search
曖昧な辞書検索
Think of it this way: the mechanism works like a dictionary search. Given a query, it finds the best matching key and returns the corresponding value. Matrix multiplication and the softmax function make this a fuzzy, differentiable version of that process.
次のように考えてみましょう。この仕組みは辞書検索のように機能します。クエリが与えられると、最も一致するキーを見つけ、対応する値を返します。行列の乗算とソフトマックス関数を使うと、このプロセスを曖昧さを扱え、かつ微分可能な形にできます。
The model processes all tokens simultaneously. The result of is a matrix—a complete map of how every word relates to every other word in your sentence. If you focus on a single query (one row), each value is the dot product of that query against each key, acting as a weight that shows how semantically related the key is to the query.
モデルはすべてのトークンを同時に処理します。の結果は の行列で、文中のすべての単語が他のすべての単語とどう関連しているかを示す完全なマップです。単一のクエリ (1つの行) に注目すると、値はそのクエリとそれぞれのキーとのドット積となり、キーがクエリに対してどれだけ意味的に関連しているかを示す重みとして機能します。
is a scalar value—the square root of the key dimension—that stabilizes the process. It prevents the dot products from becoming too large, keeping the softmax function sensitive so the model can learn effectively.
はスカラー値(キーの次元の平方根)で、プロセスを安定させる役割を果たします。ドット積が大きくなりすぎるのを防ぎ、ソフトマックス関数の感度を保つことで、モデルが効果的に学習できるようにします。
The softmax function normalizes the weights so they sum to 1. These weights are then multiplied by the corresponding word’s embedding .
は重みを正規化し、合計を1にします。これらの重みは対応する単語の埋め込みと乗算されます。
The result is then added to the original embedding in the next step, nudging it toward related tokens. For example, if receives a high weight when processing , then shifts toward , signaling that it’s edible. Because the encoder repeats this process 6 times, the embeddings get refined through each iteration, finding more useful connections. This isn’t obvious in our small example, but when is pushed toward , it also moves closer to other tokens related to eating—helping the model better capture the structure and meaning of the input.
この結果は次のステップで元の埋め込みに加えられ、その位置を関連するトークンの方向にずらします。例えば、を処理する際にが高い重みを受け取ると、はの方向にシフトすることで、それが食べられることを示します。エンコーダーはこのプロセスを6回繰り返すので、埋め込みは反復ごとに洗練され、より有用なつながりを見つけられるようになります。この小さな例ではわかりにくいですが、例えばがに向かって押されると、食べることに関連する他のトークンにも近づき、モデルは入力の構造と意味をより適切に捉えられるようになります。
In the encoder, , , and all derive from the input —the original English text multiplied by the matrices , , and . These matrices are learned during training to amplify or suppress different dimensions of the 512-dimensional vectors, allowing the model to focus on the most important relationships for translation.
エンコーダーでは、、、はすべて入力、つまり元の英語テキストに行列、、を掛けて求められます。これらの行列はトレーニングによって学習され、512次元ベクトルの各次元を増幅または抑制することで、モデルが翻訳に最も重要な関係に焦点を当てられるようにします。
In the encoder, this is called self-attention because it finds relationships between tokens within the same text. The decoder also uses cross-attention, which references the encoder’s output from the decoder’s output.
エンコーダーでは同じテキストの中でのトークンの関連性を求めるので、これは自己アテンション(self-attention)と呼ばれます。デコーダーではデコーダーの出力からエンコーダーの出力を参照する交差アテンション(cross-attention)も用いられます。
“Learned” here just means the numbers are adjusted through backpropagation during training. The paper doesn’t explain this process in detail since it’s standard practice for neural networks.
ここで「学習される」というのは、トレーニングによってバックプロパゲーションを通じて数値が調整されることを意味します。これはニューラルネットワークでは標準的な手法なので、論文中では詳細に説明されていません。
If you’re unfamiliar with the concept, here’s how it works: during training, the model are given many tasks and get scored based on how closely its output matches the expected answers. When the result is wrong, we calculate how much and in which direction it’s off, then backtrack through the network to propagate the error and adjust the values accordingly.
この概念に馴染みがない場合、仕組みは次のとおりです。トレーニングの間、モデルには多くのタスクが与えられ、出力が期待される答えにどれだけ近いかに基づいてスコアが付けられます。結果が間違っている場合、どれだけ、どの方向にずれているかを計算し、ネットワークを逆にたどってエラーを伝播させ、値を調整します。
Multihead attention
マルチヘッドアテンション
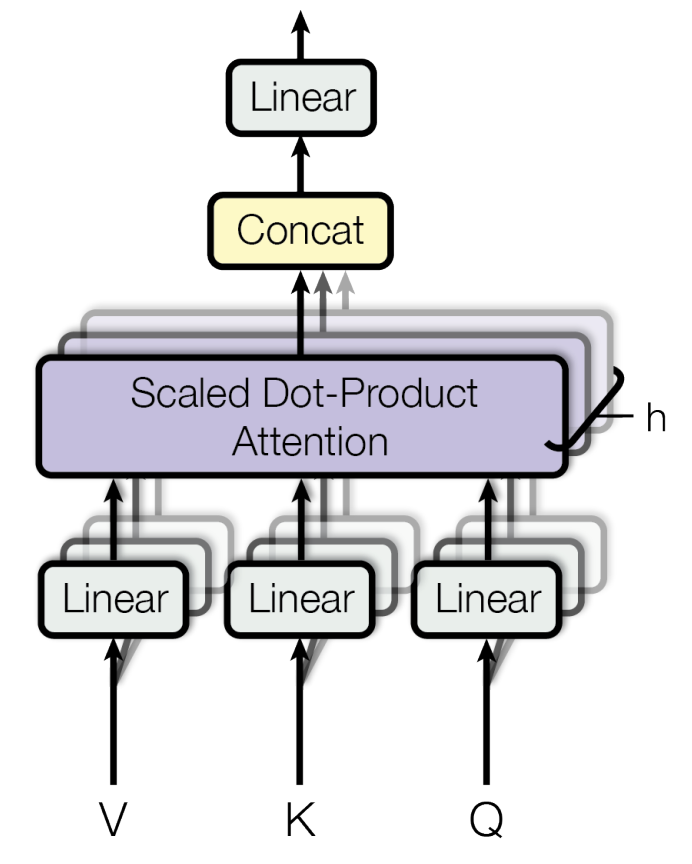
When we compare the query and key, taking the dot product of all 512 dimensions considers all aspects of the words at once. This approach misses the nuance of “in what way” these concepts are similar. Words can relate in different ways: by grammatical role, category, subject, or emotion.
クエリとキーを比較する際、512次元すべてのドット積を取ると、単語のあらゆる側面が一度に考慮されます。しかし、このアプローチでは、これらの概念が「どのような点で」類似しているかというニュアンスが見えにくくなります。単語は文法的役割、カテゴリー、主題、感情など、さまざまな観点から関連し得るからです。
Multi-head attention addresses this by dividing the vector into multiple sub-vectors (8 in this paper) to assess different aspects separately. This approach is more practical than theoretical—the number of divisions is arbitrary and still mixes 64 dimensions together. However, experiments prove it works effectively. The authors also found that dividing too much isn’t beneficial.
マルチヘッドアテンションは、ベクトルを複数のサブベクトル(この論文では8つ)に分割し、異なる側面を個別に評価します。このアプローチは理論的というよりは実用的なものです。分割数に明確な根拠はなく、それぞれのヘッドはまだ64次元をまとめて扱っています。しかし実験では、この手法が効果的に機能することが証明されました。著者らはまた、分割しすぎても効果が上がらないことも発見しました。
Note that another matrix is multiplied after concatenating the separated attentions. This allows the model to learn how to coordinate the output between the heads working in parallel.
分割されたアテンションを連結した後、別の行列が掛けられることに注意してください。これにより、モデルは並列で動作するヘッド間の出力を調整する方法を学習できます。
Add and Norm
加算と正規化
The Add & Norm step is a two-part process: Residual Connection (Add) and Layer Normalization (Norm). This is briefly touched upon in Section 3.1:
加算と正規化(Add & Norm)ステップは、残差結合(Add)と層正規化(Norm)の2つのプロセスで構成されています。これについてはセクション3.1で簡単に触れられています。
That is, the output of each sub-layer is , where is the function implemented by the sub-layer itself.
つまり、各サブレイヤーの出力は となる。ここではサブレイヤー自体によって実装される関数である。
Add
加算
() adds the input of the sub-layer (attention) back to its output. This is the nudging we discussed in the pre. In theory, a model could learn to preserve the original information and add changes simultaneously, but that would make the training much harder and unstable. By adding the input back automatically, we free the model to focus purely on the adjustments. It’s much easier to refine a shape than to recreate it from scratch at every step. This is called residual training.
()は、サブレイヤー(アテンション)の入力を出力に加算します。これは前述した、埋め込みの位置を動かす処理です。理論上はモデルに元の情報を保持しながら同時に変更を加えるよう学習させることもできますが、それではトレーニングがずっと難しく不安定になります。入力を自動的に加算することで、モデルは調整のみに集中でき、個々のステップでゼロから作り直すよりも、既存の形を洗練させる方がはるかに簡単です。これは残差学習と呼ばれます。
Norm
正規化
After adding the input back, the result is normalized so that the values have a mean of 0 and a variance of 1. This prevents the values from exploding or shrinking too much. The paper doesn’t explain this process but only cites the original Layer Normalization paper (Ba et al., 2016) as it is a standard industry practice.
入力を加算した後、結果は平均0、分散1になるように正規化されます。これにより、値が極端に大きくなったり小さくなったりするのを防ぎます。AIの世界では一般的な手法なので、論文ではこのプロセスの詳細は説明されておらず、元のLayer Normalization論文(Ba et al., 2016)が引用されているだけです。
Attention layers in the decoder
デコーダーのアテンション層
Let’s see how attention layers work on the decoder side. The mechanism is the same as in the encoder, but it serves different purposes with different inputs .
デコーダー側でアテンション層がどのように機能するか見ていきましょう。仕組みはエンコーダーと同じですが、異なる入力によって異なる目的を果たします。
Masked multi head attention
マスク付きマルチヘッドアテンション
In this layer, all come from the sentence already generated (self-attention). The goal is to let the model examine the words it has already produced and understand their relationships similar to the encoder’s attention.
この層では、のすべてが既に生成された文から来ています(自己アテンション)。モデルが生成済みの単語を調べ、それらの関係を理解できるようにすることが目的で、エンコーダーのアテンションと似た働きをします。
Masking is introduced to hide all “future” positions. For each token, the model hides all subsequent tokens by setting the scores (the result of ) to before softmax. This ensures that the representation of each token is only affected by the tokens before it. During training, this is also used to recreate the state of mid-sentence generation. While the training data contains complete translated sentences, by hiding tokens beyond a certain position, the model can simulate the scenario of generating the continuation from an incomplete state.
マスキングは、すべての「未来」の位置を隠すために導入されます。それぞれのトークンに対して、モデルはソフトマックスの前にスコア(の結果)をに設定し、後続のすべてのトークンを隠します。これにより、それぞれトークンの表現は、それより前のトークンのみから影響を受けます。トレーニング時には、文章の生成途中の状態を再現するのにも使われます。トレーニング用のデータとしては翻訳後の文章は完全にできあがっているのですが、ある場所から先のトークンを隠すことによって、まだ未完成の状態から続きを生成する場面を再現できるのです。
As the result of this process (plus the add and norm after), all the tokens will be contextualized with the relationship with the tokens before them.
このプロセス(およびその後の加算と正規化)を経て、すべてのトークンは、それより前のトークンとの関係に基づいてコンテキスト化されます。
Encoder-Decoder Attention
エンコーダー・デコーダー間のアテンション
The second attention sub layer is the bridge between the two halves of the architecture. comes from the previous layer—what has been generated so far, processed by the masked attention we discussed right above. and come from the encoder’s final output.
2つ目のアテンションサブレイヤーは、アーキテクチャの両側を結ぶ橋渡しです。 は前の層から来ます。つまり、すぐ上で説明した通りこれまでに生成された内容をマスク付きアテンションで処理したものです。とはエンコーダーの最終出力から来ます。
The goal here is to let the decoder pick the most relevant information from the source sentence based on the word it is currently trying to generate. This updates the representation of every token in the decoder sequence based on relevant information from the encoder - contextualized tokens from the source text.
ここでの目的は、デコーダーが現在生成しようとしている単語に基づいて、元の文から最も関連性の高い情報を選択することです。これにより、デコーダー内のそれぞれのトークンの表現が、エンコーダーからの関連情報、つまり元のテキストから文脈化されたトークンに基づいて更新されます。
Feed Forward
フィードフォワード
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between.
アテンションサブレイヤーに加えて、エンコーダーとデコーダーの各層には、完全連結型のフィードフォワードネットワークが含まれ、それぞれの位置に対して個別かつ同一に適用される。これは2つの線形変換と、その間に挟まれたReLU活性化関数で構成される。
The Feed-Forward Network (FFN) is the final sub-layer within each of the 6 layers of both the encoder and decoder.
フィードフォワードネットワーク(FFN)は、エンコーダーとデコーダーの両方の6層それぞれにおける最後のサブレイヤーです。
Here, is the vector ( dimensions) from the previous attention sub-layer. is a matrix that expands the input, and is a matrix that condenses it back. and are biases of size and , respectively. The is the ReLU activation function, which introduces the non-linearity required for complex reasoning.
ここで、は前のアテンションサブレイヤーからのベクトル(次元)です。はの行列で入力を拡張し、はの行列でそれを元に戻します。とはそれぞれサイズとのバイアスです。はReLU活性化関数で、複雑な推論に必要な非線形性を導入します。
All parameters () are trainable. The same process and parameters are applied to each vector, meaning the model uses consistent learned rules regardless of a word’s position in the sentence. As we’ll see on the next page, positional information is encoded in the tokens themselves, not in the logic, and the parameter can respond to this information tooo.
すべてのパラメータ()は学習可能です。同じプロセスとパラメータが全てのベクトルに適用されるため、モデルは文中の単語の位置に関係なく、一貫した学習済みのルールを使用します。次のページで見るように、位置の情報はロジック側の仕組みではなくトークン自体にエンコードされており、パラメータはこの情報にも反応します。
If the attention layers are to handle contextual processing looking at all the tokens at once, these feed-forward layers form the core of the model’s brain that looks at each token individually in depth. Because they’re generic, it’s hard to describe exactly what they do, but all these parameters are adjusted through training to process the information toward generating the expected outcomes (see Neural Network ニューラルネットワーク for the general architecture of neural networks).
アテンション層がすべてのトークンを一度に見て文脈を処理するのに対し、フィードフォワード層はそれぞれのトークンを個別に詳しく見るモデルの中核を成します。汎用的な仕組みなので、正確に何をしているかを説明するのは難しいですが、これらのパラメータはトレーニングを通じて調整され、期待される結果を生成するように情報を処理します(ニューラルネットワークの一般的なアーキテクチャについてはNeural Network ニューラルネットワークを参照してください)。
So what?
結局どうなるのか
Both the encoder and decoder repeat this process multiple (6) times to refine the information. In the end, we get the last vector from the decoder stack: the representation of the most recent token enriched with all relevant context from the source text and the tokens generated so far. This vector informs the prediction of the next token in the final step.
エンコーダーとデコーダーは両方ともこのプロセスを6回繰り返し、情報を洗練させます。最終的に、デコーダーのスタックから最後のベクトルが取り出されます。これは直前に生成されたトークンに、元のテキストとこれまでに生成されたトークンからの関連する文脈すべてを反映したものです。このベクトルが、最終ステップで次のトークンの予測に使われます。
The key difference between the transformer and previous models is the design of the attention layer. When processing each token, the model sees all other contexts, all inputs and all previous tokens, directly at once. This offers advantages in both parallelizing the process and understanding relationships between tokens regardless of their positional distance.
トランスフォーマーと従来のモデルとの主な違いは、アテンション層の設計です。それぞれのトークンを処理する際、モデルはすべての入力とすべての前のトークンを一度に直接参照します。これにより、処理の並列化と、位置に関係なくトークン間の関係を理解できるという利点が得られます。
Next
On the next page, we’ll cover the other key layers we left out: the positional encoding in the beginning, and linear and softmax at the end.
次のページでは、ここで触れなかった他の重要な層について説明します。冒頭の位置エンコーディングと、最後の線形層とソフトマックスです。